A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems

|

|

|

|

|

|

|

|

|

|

|

|
|
|
|
|
|
|
|
|
|
|
|
|
|
Reasoning is a fundamental cognitive process that enables logical inference, problem-solving, and decision-making. With the rapid advancement of large language models (LLMs), reasoning has emerged as a key capability that distinguishes advanced AI systems from conventional models that empower chatbots. In this survey, we categorize existing methods along two orthogonal dimensions: (1) Regimes, which define the stage at which reasoning is achieved (either at inference time or through dedicated training); and (2) Architectures, which determine the components involved in the reasoning process, distinguishing between standalone LLMs and agentic compound systems that incorporate external tools, and multiagent collaborations. Within each dimension, we analyze two key perspectives: (1) Input level, which focuses on techniques that construct high-quality prompts that the LLM condition on; and (2) Output level, which methods that refine multiple sampled candidates to enhance reasoning quality. This categorization provides a systematic understanding of the evolving landscape of LLM reasoning, highlighting emerging trends such as the shift from inference-scaling to learning-to-reason (e.g., DeepSeek-R1), and the transition to agentic workflows (e.g., OpenAI Deep Research, Manus Agent). Additionally, we cover a broad spectrum of learning algorithms, from supervised fine-tuning to reinforcement learning such as PPO and GRPO, and the training of reasoners and verifiers. We also examine key designs of agentic workflows, from established patterns like generator-evaluator and LLM debate to recent innovations. Finally, we identify emerging trends, such as domain-specific reasoning systems, and open challenges, such as evaluation and data quality. This survey aims to provide AI researchers and practitioners with a comprehensive foundation for advancing reasoning in LLMs, paving the way for more sophisticated and reliable AI systems
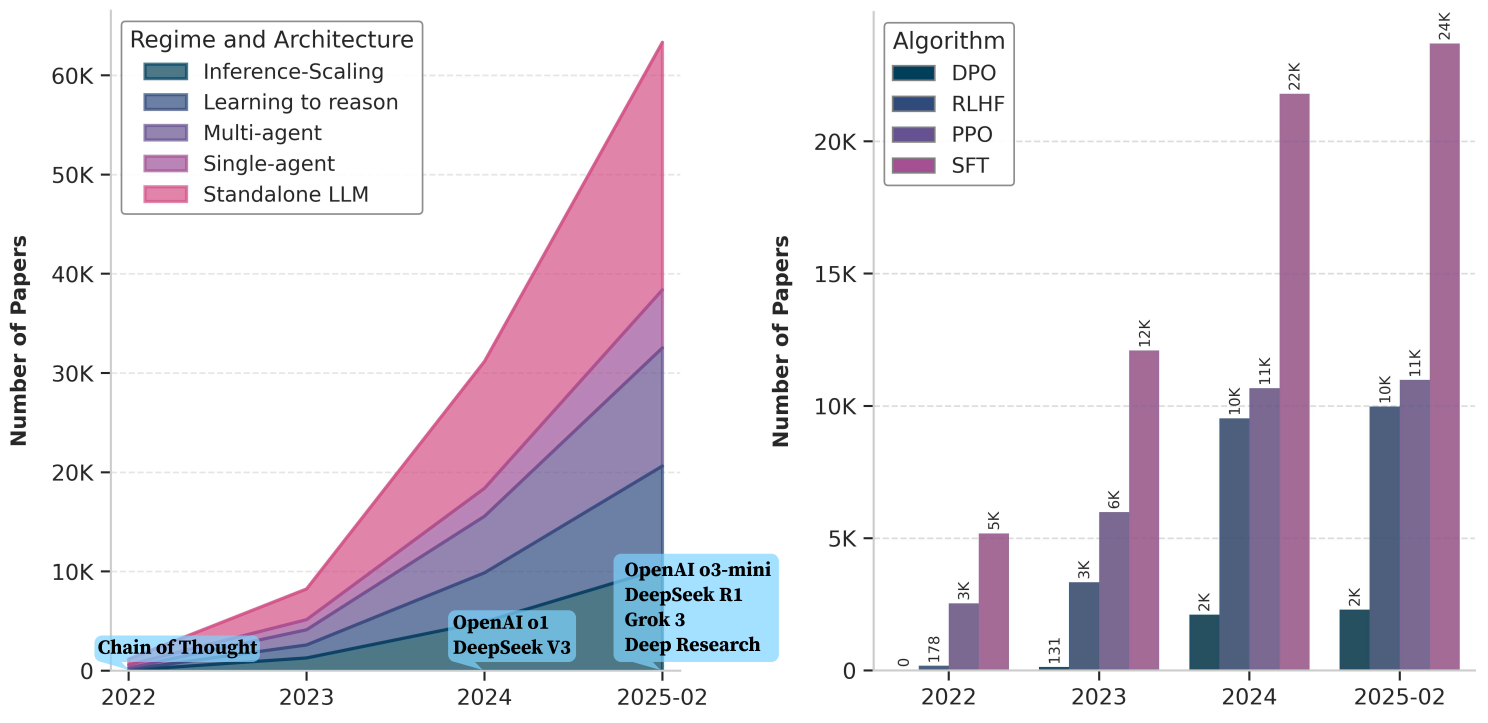
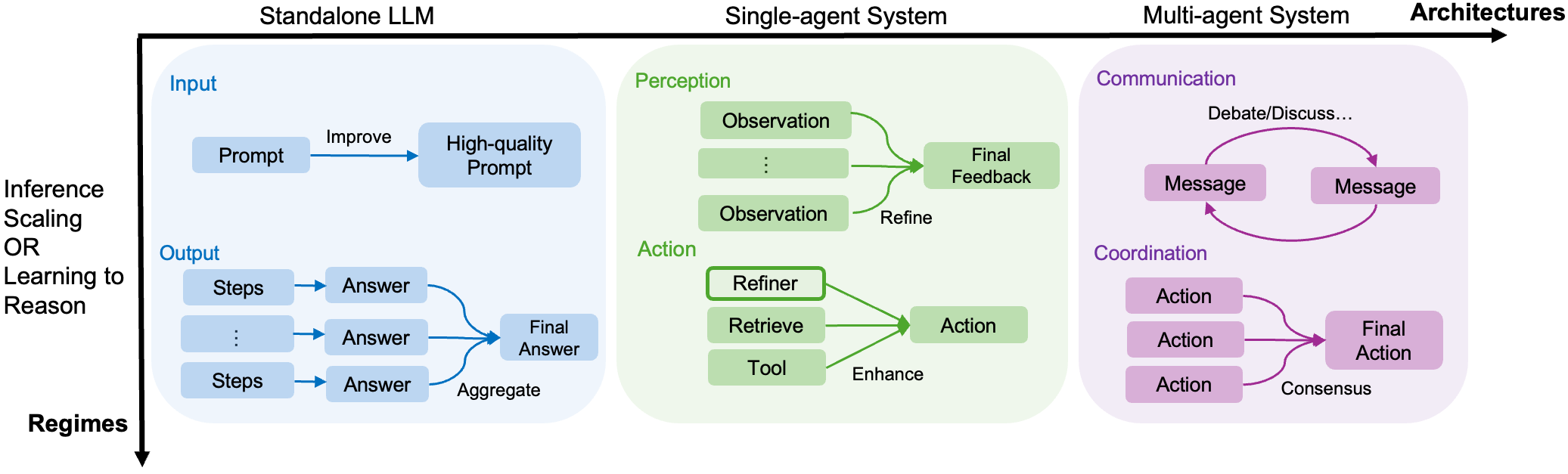
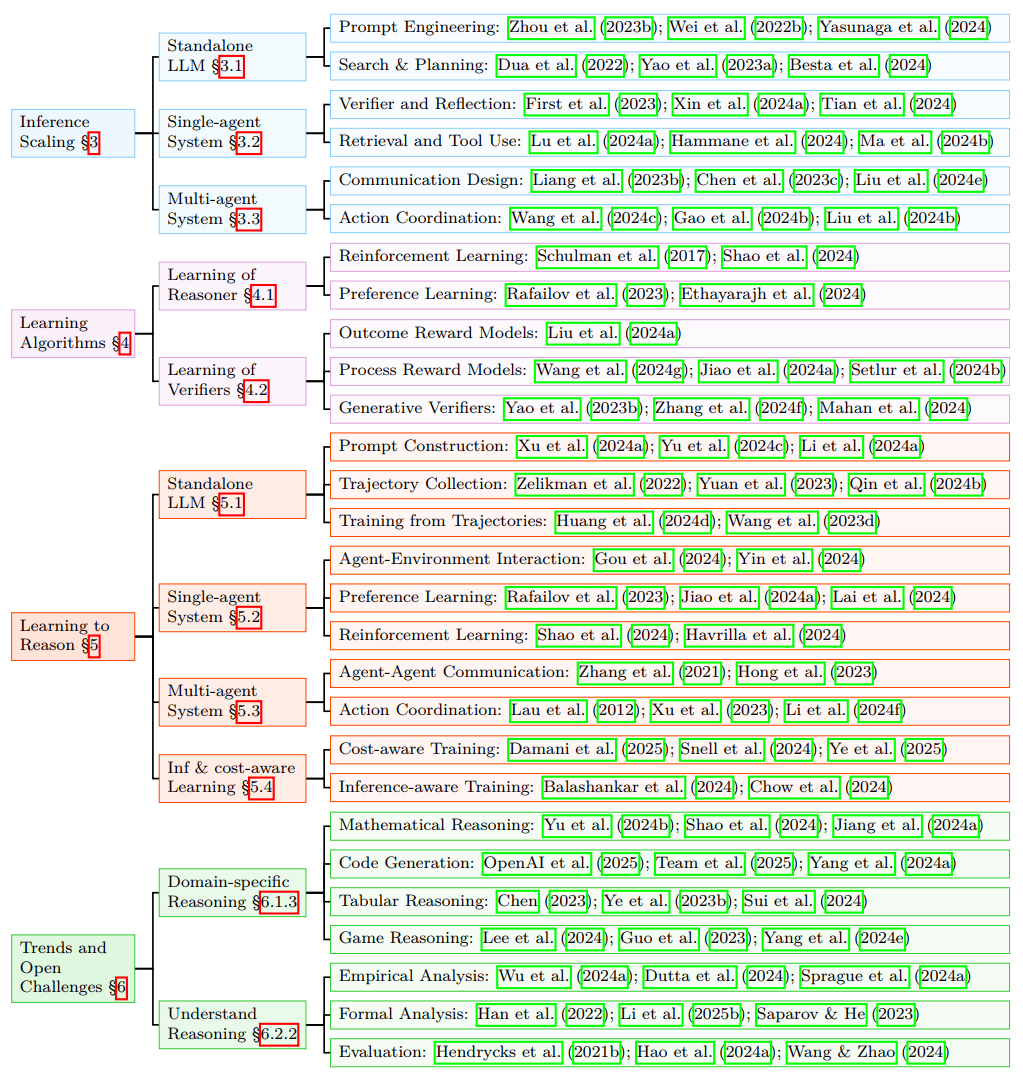
As shown in Figure 1, this area has rapidly gained research attention, often referred to as LLM reasoning or reasoning language model. Reasoning requires LLMs to go beyond directly producing an answer from a question; instead, they must generate the thinking process (implicitly or explicitly) in the form of 'question → reasoning steps → answer'. Building on this, the ability of LLMs to reason effectively depends on two factors: how and at what stage reasoning is achieved, and what components are involved in the reasoning process. Accordingly, in this survey, we categorize existing research into two orthogonal dimensions (Figure 2): (1) Regime, refers to whether reasoning is achieved through inference-time strategies (aka. inference-time scaling) or through direct learning and adaptation (learning to reason); and (2) Architecture, refers to whether reasoning happens within a single, standalone LLM or within an interactive, agentic system. Figure 3 outlines the structure of this survey.
@misc{ke2025surveyfrontiersllmreasoning,
title={A Survey of Frontiers in LLM Reasoning: Inference Scaling, Learning to Reason, and Agentic Systems},
author={Zixuan Ke and Fangkai Jiao and Yifei Ming and Xuan-Phi Nguyen and Austin Xu and Do Xuan Long and Minzhi Li and Chengwei Qin and Peifeng Wang and Silvio Savarese and Caiming Xiong and Shafiq Joty},
year={2025},
eprint={2504.09037},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2504.09037},
}